Enterprise Dmg-18s Engine
Once it is converted to ISO file format, then it can be burned to CD or DVD in Windows OS. Even you can mount the ISO file in the and use it. Free dmg to iso converter.
- Enterprise Dmg-18s Engine Parts
- Enterprise Dmg-18s Engine Problems
- Enterprise Dmg-18s Engine For Sale
- Enterprise Dmg-18s Engine Repair
Find marine exhaust articles, the world’s largest environmental industry marketplace and information resource. Enterprise Support for Chrome Browser. Get best practices, troubleshoot potential issues, and avoid user downtime with Chrome Browser Enterprise Support. Available to organizations with over 1,000 users, this service offers 24/7 assistance from a team of Google experts. Contact sales to buy. Or visit our Help Center for support articles. In October of 2009, Winnipesaukee Flagship Corporation undertook a project to repower the excursion vessel Mt. Washington, with funding from EPA 2009 DERA. The old engines in the Mt. Washington were two 1946 Enterprise DMG-18s, each producing 615 HP. The Enterprise engines were pre-regulation EPA Tier 0 engines, and emitted much more NOx and PM than their contemporary.
Enterprise search is the practice of making content from multiple enterprise-type sources, such as databases and intranets, searchable to a defined audience [1].
'Enterprise search' is used to describe the software of search information within an enterprise (though the search function and its results may still be public).[2] Enterprise search can be contrasted with web search, which applies search technology to documents on the open web, and desktop search, which applies search technology to the content on a single computer.
Enterprise search systems index data and documents from a variety of sources such as: file systems, intranets, document management systems, e-mail, and databases. Many enterprise search systems integrate structured and unstructured data in their collections.[3] Enterprise search systems also use access controls to enforce a security policy on their users.[4]
Enterprise search can be seen as a type of vertical search of an enterprise.
- 1Components of an enterprise search system
- 4Access control: early binding vs late binding
Components of an enterprise search system[edit]
In an enterprise search system, content goes through various phases from source repository to search results:
Content awareness[edit]
Content awareness (or 'content collection') is usually either a push or pull model. In the push model, a source system is integrated with the search engine in such a way that it connects to it and pushes new content directly to its APIs. This model is used when realtime indexing is important. In the pull model, the software gathers content from sources using a connector such as a web crawler or a database connector. The connector typically polls the source with certain intervals to look for new, updated or deleted content.[5]
Content processing and analysis[edit]
Content from different sources may have many different formats or document types, such as XML, HTML, Office document formats or plain text. The content processing phase processes the incoming documents to plain text using document filters. It is also often necessary to normalize content in various ways to improve recall or precision. These may include stemming, lemmatization, synonym expansion, entity extraction, part of speech tagging.
As part of processing and analysis, tokenization is applied to split the content into tokens which is the basic matching unit. It is also common to normalize tokens to lower case to provide case-insensitive search, as well as to normalize accents to provide better recall.
Enterprise Dmg-18s Engine Parts
Indexing[edit]
The resulting text is stored in an index, which is optimized for quick lookups without storing the full text of the document. The index may contain the dictionary of all unique words in the corpus as well as information about ranking and term frequency.
Query processing[edit]
Using a web page, the user issues a query to the system. The query consists of any terms the user enters as well as navigational actions such as faceting and paging information.
It has the video decoding capabilities that reduces the CPU load but it can only be workable only if snow leopard gets installed on mac with nVidia Get fore 9400M or GT 330 graphic codes.The requirements of Quick Time X involves the insight, USB class, and FireWire DV camcorder camera.Multi-TouchThe snow leopard multi-touch trackpad is now introduced in the notebooks, removing the limitation of gestures. This was the next version of quick time framework and multimedia. Now it enables the four finger gestures and improves the qualityPreview of filesThis features to support the paragraph preview in the form of PDF and improves the readability.Time MachineSupported the connections and made them even faster than before.For this, a separate hard drive is required or much other time capsule has been sold.Safari 4The issue of browser crashing has been removed by the introduction and support of Safari 4 feature. Crashes occurred due to the plugins or processing the browser in a separate processor. 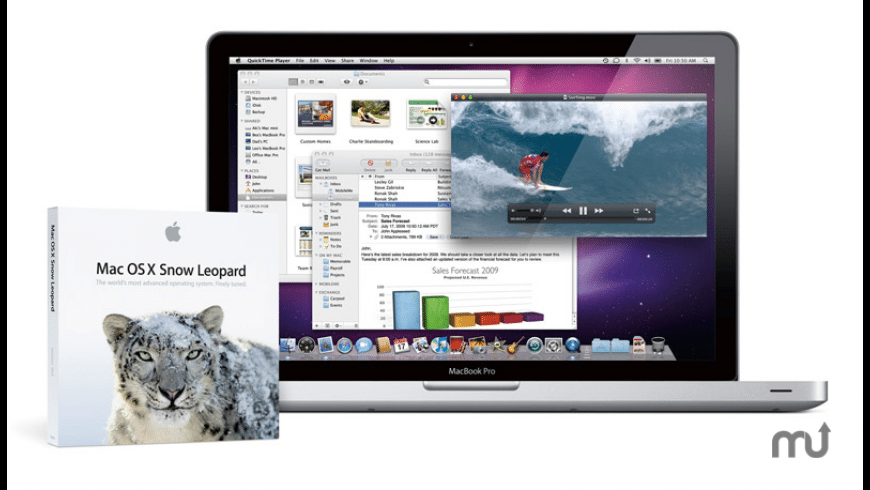 To deliver the playback, it has been designed on the technology like core audio core video and core animation.It supports the HTTP live streamlining and the feature of Color Sync enhance the results and display of the videos.
To deliver the playback, it has been designed on the technology like core audio core video and core animation.It supports the HTTP live streamlining and the feature of Color Sync enhance the results and display of the videos.
Matching[edit]
The processed query is then compared to the stored index, and the search system returns results (or 'hits') referencing source documents that match. Some systems are able to present the document as it was indexed.
Differences from web search[edit]
Beyond the difference in the kinds of materials being indexed, enterprise search systems also typically include functionality that is not associated with the mainstream web search engines. These include:
- Adapters to index content from a variety of repositories, such as databases and content management systems.
- Federated search, which consists of
- transforming a query and broadcasting it to a group of disparate databases or external content sources with the appropriate syntax,
- merging the results collected from the databases,
- presenting them in a succinct and unified format with minimal duplication, and
- providing a means, performed either automatically or by the portal user, to sort the merged result set.
- Enterprise bookmarking, collaborative tagging systems for capturing knowledge about structured and semi-structured enterprise data.
- Entity extraction that seeks to locate and classify elements in text into predefined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
- Faceted search, a technique for accessing a collection of information represented using a faceted classification, allowing users to explore by filtering available information.
- Access control, usually in the form of an Access control list (ACL), is often required to restrict access to documents based on individual user identities. There are many types of access control mechanisms for different content sources making this a complex task to address comprehensively in an enterprise search environment (see below).
- Text clustering, which groups the top several hundred search results into topics that are computed on the fly from the search-results descriptions, typically titles, excerpts (snippets), and meta-data. This technique lets users navigate the content by topic rather than by the meta-data that is used in faceting. Clustering compensates for the problem of incompatible meta-data across multiple enterprise repositories, which hinders the usefulness of faceting.
- User interfaces, which in web search are deliberately kept simple in order not to distract the user from clicking on ads, which generates the revenue. Although the business model for enterprise search could include showing ads, in practice this is not done. To enhance end user productivity, enterprise vendors continually experiment with rich UI functionality which occupies significant screen space, which would be problematic for web search.
Relevance factors[edit]
The factors that determine the relevance of search results within the context of an enterprise overlap with but are different from those that apply to web search. [1] In general, enterprise search engines cannot take advantage of the rich link structure as is found on the web's hypertext content, however, a new breed of Enterprise search engines based on a bottom-up Web 2.0 technology are providing both a contributory approach and hyperlinking within the enterprise. Algorithms like PageRank exploit hyperlink structure to assign authority to documents, and then use that authority as a query-independent relevance factor. In contrast, enterprises typically have to use other query-independent factors, such as a document's recency or popularity, along with query-dependent factors traditionally associated with information retrieval algorithms. Also, the rich functionality of enterprise search UIs, such as clustering and faceting, diminish reliance on ranking as the means to direct the user's attention.
Access control: early binding vs late binding[edit]
Security and restricted access to documents is an important matter in enterprise search. There are two main approaches to apply restricted access: early binding vs late binding.[6]
Late binding[edit]
Permissions are analyzed and assigned to documents at query stage. Query engine generates a document set and before returning it to a user this set is filtered based on user access rights. It is costly process but accurate (based on user permissions at the moment of query).
Early binding[edit]
Permissions are analyzed and assigned to documents at indexing stage. It is much more effective than late binding, but could be inaccurate (user might be granted or revoked permissions between in the period between indexing and querying).
Search relevance testing options[edit]
Search application relevance can be determined by following relevance testing options like[7]
- Focus groups
- Reference evaluation protocol (based on relevance judgements of results from agreed-upon queries performed against common document corpuses)
- Empirical testing
- Log analysis on a Beta production site
- Online ratings
See also[edit]
Enterprise Dmg-18s Engine Problems
References[edit]
- ^ abKruschwitz, Udo; Hull, Charlie (2017). 'Searching the Enterprise'. Foundations and Trends in Information Retrieval. 11: 1–142. doi:10.1561/1500000053.
- ^'What is Enterprise Search?'.
- ^'The New Face of Enterprise Search: Bridging Structured and Unstructured Information'(PDF). Archived from the original(PDF) on 2015-10-28. Retrieved 2013-05-27.
- ^'Security Requirements to Enterprise Search: part 1 - New Idea Engineering'.
- ^'Understanding Content Collection and Indexing'.
- ^'Enterprise Search: document access control'. Archived from the original on 2014-12-08. Retrieved 2014-12-01.
- ^'Debugging Search Application Relevance Issues'. Archived from the original on 2013-06-05. Retrieved 2013-05-27.
Enterprise Dmg-18s Engine For Sale
